When managing a website, especially after a migration or extensive content pruning, it’s common to end up with hundreds or even thousands of 404 errors (broken pages). I’ve found that redirect mapping is a lifesaver, but it gets tricky when URLs don’t match perfectly. Handling these manually is tedious, but with some Python can automate this process effectively using the machine learning approach of string matching or otherwise known as fuzzy matching.
This tutorial will show you two very similar to one another use cases of fuzzy matching:
- Mapping 404s to existing content (broken to somewhat similar live pages) using different fuzzy matching methods and generate a redirect list
- Mapping old to new URLs following a site migration, with the aim of error correction and maintaining SEO value.
If you’d like to learn more about fuzzy matching and string matching, my course Introduction to Machine Learning for SEOs, includes an entire module on these approaches, algorithms, and marketing and SEO project implementations, and use cases.
Curious about fuzzy matching? ✨
Go beyond free tools—enroll now and master ML-enabled organic marketing

BEGINNER-FRIENDLY COURSE TO UNDERSTAND AI AND ML
Introduction to Machine Learning for SEOs
This course offers a step-by-step introduction to machine learning tailored for SEO professionals. Learn how to improve your processes using AI/ML, including automating tasks, analyzing large data sets, and improving content strategies. Perfect for SEOs seeking a competitive edge but also to really understand the nuts and bolts of ML.
Understanding the problem and the ML solution
404 errors and redirect mapping are central to maintaining a functional and user-friendly website. Understanding their purpose and connection can streamline your efforts in managing broken links effectively.
Understanding 404s and the impact they could have
404 errors occur when a requested URL cannot be found on the server. These indicate that a page is missing or the link used to access it is incorrect. For instance, users may see a “Page Not Found” message after clicking on outdated links or mistyped URLs. Search engines may penalize websites with excessive 404 errors because they impact user experience negatively.
Why redirect mapping matters in migration projects
Redirect mapping ensures users and search engines reach alternative relevant pages when encountering broken links. This helps retain site traffic that would otherwise be lost due to missing pages. For example, redirecting an outdated blog post to a similar updated article improves engagement and reduces bounce rates. Proper mapping also protects your site’s SEO performance by preserving link equity and avoiding disruptions in user navigation.
Understanding Fuzzy String Matching and what it does
Fuzzy matching finds similarity between imperfect or inconsistent data sets, such as mistyped URLs or varied naming conventions. In redirect mapping, this technique identifies potential alternative pages to replace broken ones. For example, fuzzy matching can link “/product123” and “/product-123” despite their minor differences. Using fuzzy matching in Google Colab simplifies URL analysis and decision-making, enabling efficient resolution of 404 errors with computational tools.
The beauty of fuzzy matching is that it’s:
- Flexible — minor typos, slug changes, and naming variations don’t block matches.
- Scalable — thousands of URLs can be processed in minutes in Google Colab.
- Customizable — you decide what’s “similar enough” with adjustable thresholds.
Use Case 1: 404 URL Mapping (Broken → Live Pages)
Grab a copy of the featured Python Scripts from this blog post:
The workflow (step-by-step)
- Get your URL lists.
Crawl your site and export 2xx (live) and 4xx (broken) URLs as CSVs. - Open the Colab notebook and upload.
You’ll be prompted to upload the 404s CSV first, then the live URLs CSV. - Confirm the root domain.
Enter your root domain. The notebook checks both files and flags any URLs that don’t match your domain. You can:- proceed and automatically remove them (recommended if counts are small), or
- abort and do heavier pre-processing.
- Light pre-processing.
We strip the root domain from paths to speed up matching and convert columns to lists.
(You can extend this later — more on that below.) - Run similarity functions across libraries.
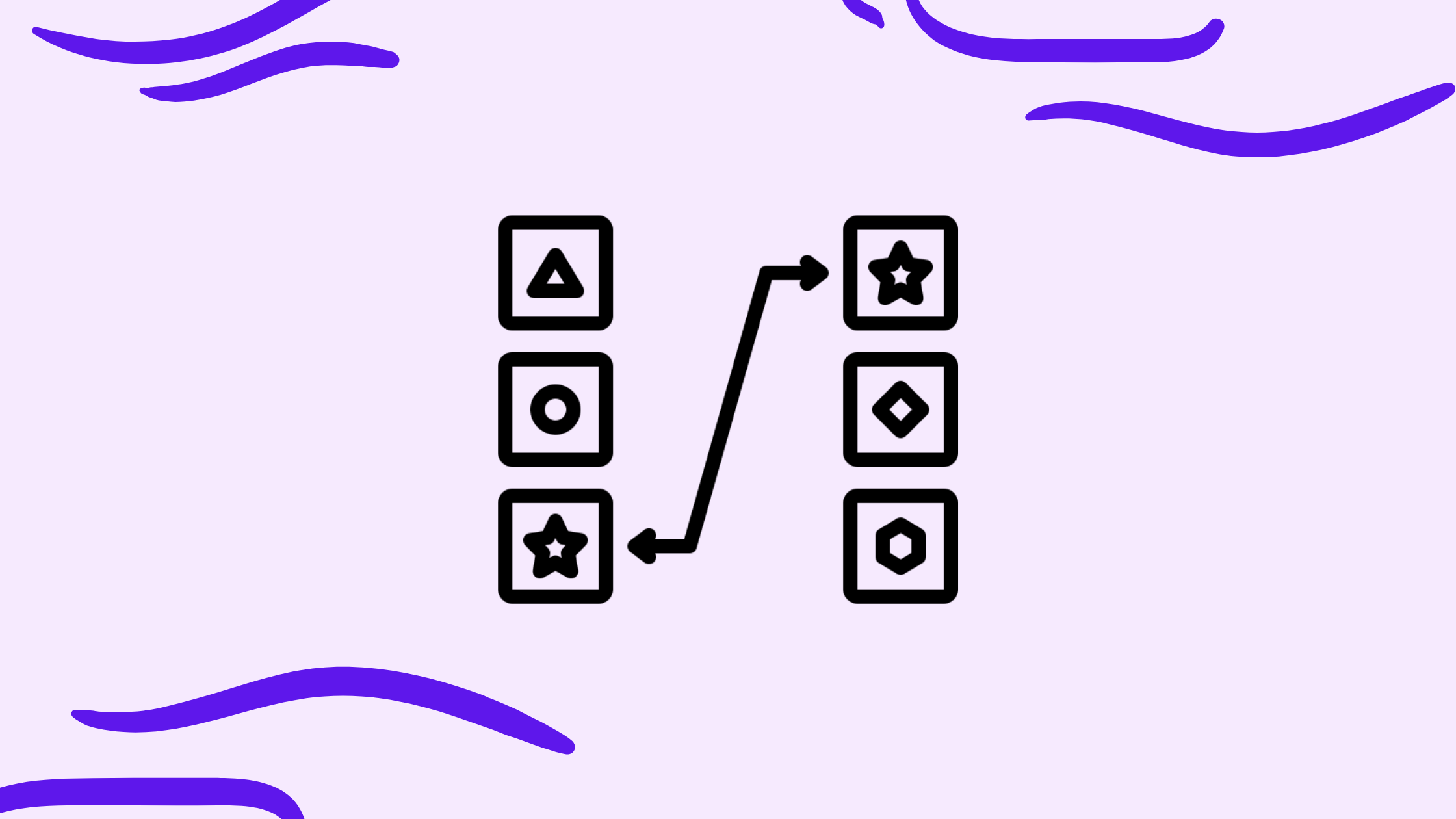
The notebook includes multiple approaches (e.g., PolyFuzz, RapidFuzz, Levenshtein/FuzzyWuzzy). Feel free to comment out what you don’t need — but my suggestion would be to compare and contrast outputs first. - Generate your redirect list.
You’ll get candidates (404 → live URL) and downloadable files. The default formatting is .htaccess friendly, but you can tweak the output to match your stack.
Evaluating the output (what “good” looks like)
- Expect semantically close matches even though we’re doing string comparisons.
Example from my dataset:/how-do-computers-actually-remember↔/how-do-computers-actually-compute/mathematics-i-would-look-for-in-data-science-interviews↔/machine-learning-basics-i-would-look-for-in-data-science-interviews
Intent is aligned; a redirect is reasonable.
- Be mindful of filters and thresholds.
If you set a similarity cutoff (e.g., 75%) and normalize scores, some frames may return empty. That doesn’t mean the library failed — it means the filter is strict. Adjust and re-run. - Human QA is non-negotiable.
Even strong matches can be wrong for your brand, UX, or business logic. Review before implementing.
Ways to improve (process enhancement opportunities)

Tune thresholds per group.
Blog posts, product pages, and docs may need different similarity cutoffs. Calibrate per cluster for cleaner results.
Invest in dataset prep.
Remove authors, tags, categories, or other templates if you plan to handle them differently from content pages. Group 404s by handling strategy before you run matching.
Add metadata into the matching.
Incorporate titles (and available metadata) alongside slugs for better signals.
Pre-process slugs + identify entities.
Parse slugs, extract tokens, and run entity recognition on slugs/titles.
Then cluster both broken and live URLs by topic/entity and match within clusters. This injects lightweight “semantic” structure without heavy ML.
Use Case 2: Redirect Mapping (Old → New After Migration)
The context
A migration happened. You have pre-migration and post-migration crawls, and now you want a fast, auditable map from old to new.

Grab a copy of the featured Python Scripts from this blog post:
The workflow (step-by-step)
- Export comparable fields.
From both datasets, include as many of the following as you have:
URL/Address, Title, H1, H2 (one or two columns), Meta Description.
(You can still run with fewer; the functions are modular.) - Upload “old” first, then “new”.
The notebook will process pairs across dimensions. - Define match functions.
We compare like-to-like (URL↔URL, Title↔Title, H1↔H1, etc.) using multiple libraries (PolyFuzz, RapidFuzz, FuzzyWuzzy). - Use a simple 3-tier classifier, no hard cutoff.
Alongside raw similarity scores, we add a text label:- Exact match: 100%
- Partial match: 50%–<100%
- No suitable match: 0%–<50%
This is more useful than a single global threshold when reconciling migrations.
- Review and export.
Filter by dimension (URL, Title, H1…) or match type (Exact / Partial / No match).
Save your files; they’ll download automatically.
Evaluating the output (what to watch for)
- Because we don’t normalize or hard-filter here, expect noise in partials. That’s okay — the tiering helps triage. Human review is highly recommended.
- Context matters.
If meta descriptions don’t match, that may be intentional (post-migration copy refresh). Focus on URL and intent alignment first, then spot-check titles/H1s.
Ways to improve (process enhancement opportunities)
- Output ergonomics.
Re-format frames for your environment (e.g., add an .htaccess rule column, or a status column for QA sign-off). - Selective promotion of partials.
For partials above your chosen threshold (say 70%+), pre-build redirect rules but flag for manual verification.
Tips for optimizing redirect mapping
Applying specific strategies can improve both accuracy and efficiency when implementing redirect mapping with fuzzy matching techniques.
Fine-Tune Fuzzy Matching Ratios
Adjusting fuzzy matching ratios is essential for balancing precision and flexibility in URL comparisons.
- Lower thresholds (e.g., 60–70) capture more potential matches, suitable for heavily inconsistent datasets.
- Higher thresholds (e.g., 85–90) prioritize accuracy, reducing irrelevant matches, ideal for datasets with minor URL variations.
I test multiple thresholds based on dataset characteristics and use the similarity scores provided by FuzzyWuzzy’s fuzz or process modules to determine optimal values.
Improve Handling of Duplicate Or Ambiguous Matches
Resolving duplicate or ambiguous matches reduces errors in redirect suggestions. When multiple potential matches occur for a single 404 URL, I sort them by their similarity scores in descending order.
Priority is given to URLs with higher scores or those aligning with site-specific rules, such as matching keywords in page titles. Using a Pandas DataFrame, I filter and preprocess the results to ensure clarity, selecting only the top-ranked match or confirming correct associations manually if required.
Reduce False Positives In Mapping
Minimizing false positives ensures reliable redirections. I incorporate validation checks, such as verifying that suggested redirects are live and relevant to user intent, by using the Requests library to confirm HTTP status codes (e.g., 200). Custom filters exclude short-lived matches or redirects leading to the same 404 error, improving dataset reliability.
Adding a manual review step for flagged URLs enhances the process when automated methods fail to meet accuracy expectations.
Common Issues And Troubleshooting
While implementing 404 and redirect mapping with fuzzy matching in Google Colab, challenges may arise that disrupt the process. Addressing these issues promptly ensures a smoother workflow and more accurate outcomes.
- Performance bottlenecks — filter URLs before matching, split datasets, or run locally for huge projects.
- Mismatches — tweak thresholds, add keyword rules, or combine fuzzy matching with semantic/entity analysis.
- Overconfidence in automation — never skip human review, especially for ambiguous or high-impact redirects. Fuzzy matching is powerful, but it doesn’t “know” intent. Always check whether the proposed target makes sense for user search intent and brand.
Improving performance
Performance challenges often occur when processing large datasets in Google Colab. For optimization, I reduce the dataset size by filtering irrelevant URLs before analysis, ensuring only actionable data remains. Increasing Google Colab’s RAM allocation through the notebook environment settings addresses memory limitations when needed.
When runtime restrictions interfere, you can also:
- split extensive datasets into smaller subsets and process them iteratively.
- try running the script locally on your PC
- upgrade your Google Colab subscription if you insist on keeping it as your environment
Resolving Mismatched URLs
Incorrect redirect suggestions sometimes stem from suboptimal fuzzy matching configurations. To resolve this, I adjust the similarity ratio threshold in FuzzyWuzzy; lowering it captures more possible matches, whereas increasing it improves precision.
If mismatched URLs persist, I include contextual rules for prioritizing keyword relevance or path patterns during comparisons. You can also use something like entity matching on the titles, URLs, or content itself, or comparing the overall similarity scores of scraped pages, to increase the mapping precision.
Never skip out on manual review steps for flagged outputs.
Alternative methods for redirect mapping via fuzzy matching
I also wanted to highlight some alternative methods of handling 404 errors and broken links, offering expanded options for redirect mapping:
- Redirect mapping in Google Sheets (no-code) – Fuzzy Matching for SEO Use Cases [Google Sheets Template by LazarinaStoy.com] (great under ~100–300 URLs).
- Redirect mapping in Excel (no-code) –Faster Redirect Mapping with Excel Fuzzy Lookups – Chris Mann
- Redirect mapping web-based app (no-code) –Free URL Redirect Mapping Tool for Website Migrations | URL Matcher
If you’re dealing with >1,000 URLs, move to Colab/Python. You’ll get control over libraries, algorithms, data access, and output — and avoid UI ceilings.
Fuzzy matching speeds up 404 and migration mapping, improving UX and protecting SEO by resolving broken journeys quickly.
Google Colab + Python libraries (PolyFuzz, RapidFuzz, FuzzyWuzzy, Levenshtein) provide a flexible, replicable workflow.
Threshold tuning, smart pre-processing, and human QA make or break quality.
Entity-aware clustering and metadata matching boost precision without heavy ML.
For small datasets, no-code options are fine; for larger ones, use Colab for control and scale.
Now that you’ve seen how to apply fuzzy matching to 404s and migration redirects, I also want to highlight more MLforSEO content where we use string matching for different SEO and marketing use cases. If you want the end-to-end playbook — algorithms, templates, and 20+ project ideas you can implement this technique in — join Introduction to Machine Learning for SEOs.
Key Takeaways
Managing 404 errors and implementing effective redirect mapping is essential for maintaining a seamless user experience and protecting SEO performance.
Here’s a short summary on the key takeaways from this piece:
- Fuzzy matching speeds up 404 and migration mapping, improving UX and protecting SEO by resolving broken journeys quickly.
- Google Colab + Python libraries (PolyFuzz, RapidFuzz, FuzzyWuzzy, Levenshtein) provide a flexible, replicable workflow.
- Threshold tuning, smart pre-processing, and human QA make or break quality.
- Entity-aware clustering and metadata matching boost precision without heavy ML.
- For small datasets, no-code options are fine; for larger ones, use Colab for control and scale.
Now that you know how to work with fuzzy matching algorithms, I also want to highlight other MLforSEO content we have that uses string matching for different use cases.
Different ways to Map Keywords to topics – with Supervised and Unsupervised ML approaches
How to Automatically Optimize your SEO Metadata with FuzzyWuzzy and OpenAI in Google Colab
Lazarina Stoy is a Digital Marketing Consultant with expertise in SEO, Machine Learning, and Data Science, and the founder of MLforSEO. Lazarina’s expertise lies in integrating marketing and technology to improve organic visibility strategies and implement process automation.
A University of Strathclyde alumna, her work spans across sectors like B2B, SaaS, and big tech, with notable projects for AWS, Extreme Networks, neo4j, Skyscanner, and other enterprises.
Lazarina champions marketing automation, by creating resources for SEO professionals and speaking at industry events globally on the significance of automation and machine learning in digital marketing. Her contributions to the field are recognized in publications like Search Engine Land, Wix, and Moz, to name a few.
As a mentor on GrowthMentor and a guest lecturer at the University of Strathclyde, Lazarina dedicates her efforts to education and empowerment within the industry.
- Lazarina Stoy.

- Lazarina Stoy.

- Lazarina Stoy.
- Lazarina Stoy.