Learn how query context and session context shape Google’s results — and how AI search systems take personalisation even further — so you can build smarter, more relevant SEO strategies.
Every Google result is shaped by context. It’s not just the words you type, but the sequence of searches you make, the pages you click, your location, and the patterns of people like you — all of which inform which answers rise to the top. In this guide, we’ll break down two pillars of that process: query context (the meaning inside a single search) and session context (the signals across your searches), and show how they work together to refine relevance in real time.
We’ll translate these ideas into practical SEO moves: how to read macro vs. micro context in content, cluster queries that land on the same page, blend Google Search Console with GA4 to map query → landing → next-page paths, and spot intent cannibalisation when rankings wobble. You’ll also see how personalisation — at the individual and cohort level — can quietly boost popular results and demote ones users repeatedly ignore, and what to do about it.
Then, we’ll go further. Because everything Google does with session context at the ranking level, AI search systems like ChatGPT, Gemini, and Perplexity are now doing upstream — at the query generation level. We’ll explore how AI search platforms use memory and context to personalise the very questions they ask on your behalf, and what that means for content strategy.
By the end, you’ll know how to structure pages and internal links that mirror real user journeys, plan updates around recurring session patterns and trending subtopics, diagnose rank drops with context-aware thinking, and position your content to surface across the diverse user contexts that AI search systems now use to shape results.
Query context vs. session context (and why both drive relevance)
Query context is the meaning and scope that the user explicitly provides in a single query: words, modifiers, and hints that clarify intent. Session context, on the other hand, is everything the user (and users like them) implicitly contributes across a series of interactions: the order of queries, past clicks, search frequency on a topic, the kinds of pages they engage with, their physical location, and more.
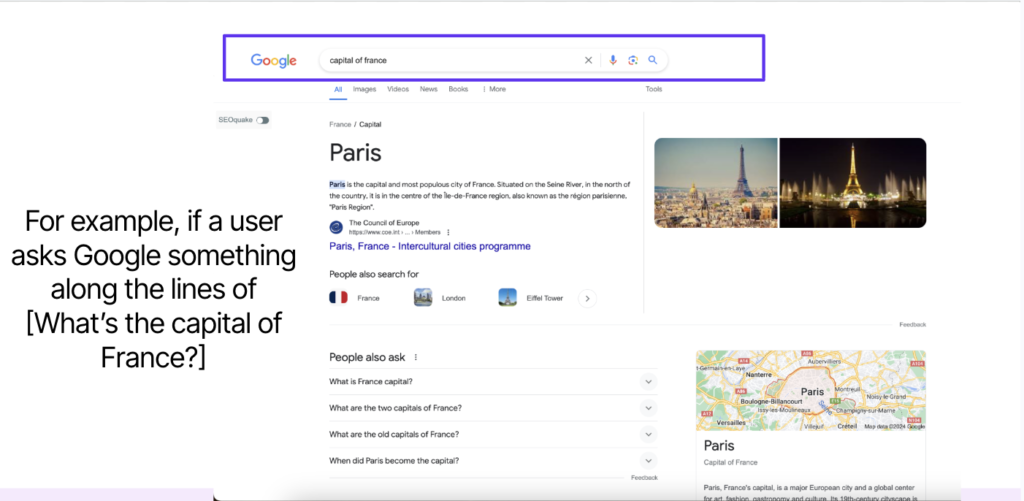
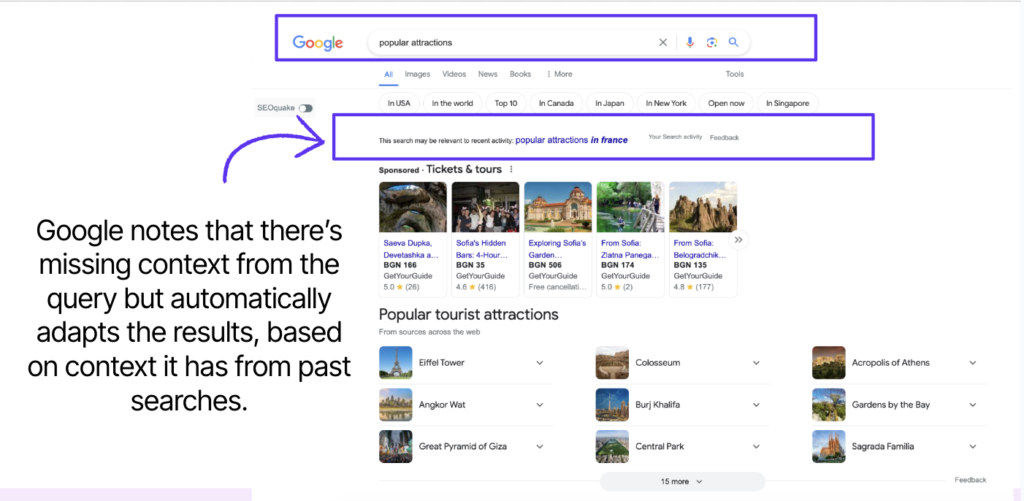
Together, these layers allow search engines to dynamically adapt results — sometimes without the user having to spell everything out. For example, if someone searches “what is the capital of France” and follows with “popular attractions,” Google can infer that “in France” remained implied, refining the second query automatically.
Even ads and commercial elements may adapt to the user’s location — showing Sofia-based ticket providers while the informational intent centres on Paris.
Macro context and micro context
Before looking at how search engines process and score relevance, it’s helpful to understand that they interpret information at two interconnected levels: macro and micro context. Together, these layers allow Google’s patents to determine both the general and the specific meaning of a query or document, refining results in ways that align with user intent rather than surface keywords.
Macro context — the broad domain fit
At the highest level, macro context refers to the primary category or domain to which a piece of content belongs. It’s how a search engine recognises that a page about “yoga for beginners” sits within the broader topic of health and fitness, not spirituality or lifestyle. This top-down understanding helps filter out irrelevant results early by narrowing the pool of potential matches to the right thematic cluster.
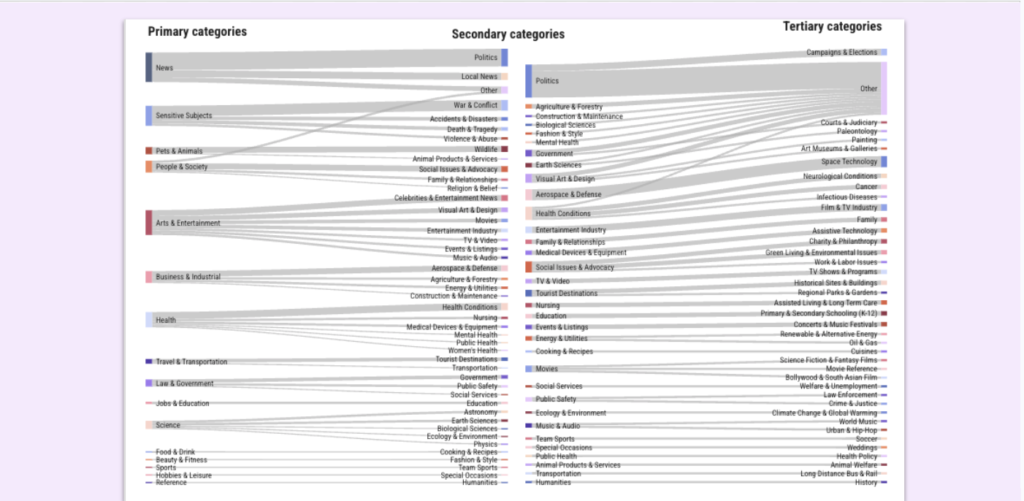
Macro context is often derived from large-scale text classification models that group content into broad fields such as medicine, technology, travel, education, sports, or finance. These categories are similar to the “primary” and “secondary” labels produced by Google’s own Text Classification API.
Once a query’s macro domain is identified, only documents that fit that domain continue through deeper evaluation, ensuring that the search results stay on topic from the start.
Micro context — fine-grained specificity
Micro context operates one layer deeper. Within a macro domain, it pinpoints the specific terms, entities, and subtopics that clarify what exactly the user means. For instance, within the macro category “Medicine,” the micro context distinguishes whether the user is interested in oncology treatments, clinical trials, or patient care.
This is where entity recognition, topic modelling, and co-occurrence analysis come into play. These models extract meaningful relationships between terms — connecting “Eiffel Tower” with “Paris,” “architect Gustave Eiffel,” or “ticket prices” — so that Google can refine the scope of relevance from a general domain (travel/tourism) to a precise task (planning a visit).
Why both layers matter
By combining macro and micro context, search engines avoid two common pitfalls: overly broad matching (showing everything remotely related to the topic) and overly narrow matching (fixating on isolated keywords). The macro layer ensures content is topically appropriate, while the micro layer fine-tunes the exact meaning and nuance of each search query.
In SEO practice, this two-tiered view explains why entity-rich, semantically structured content performs better than flat keyword repetition. When your pages clearly signal both their domain relevance (macro) and their in-depth focus (micro), you help Google understand not just what your page mentions — but what it means and where it fits in the knowledge graph.
A practical mental model of Google’s workflow
To connect the theory of the user-context-based search engine patent to how Google actually processes and ranks results, let’s walk through a simplified version of the workflow.
When a user submits a query, the search engine first receives the query along with contextual signals that help interpret its meaning. These signals include explicit elements like the words and modifiers used, as well as implicit information such as the user’s location, device, language, and the recency of the search. This combination gives the system a richer understanding of what the user is likely looking for, even when the query itself lacks precision.
Next, the engine retrieves a set of candidate documents from its index. These documents are grouped and ranked within broad topic hierarchies that correspond to the macro context — the general domain or subject area most relevant to the query. This step filters out content from unrelated categories, ensuring the system operates within the right conceptual space before moving into specifics.
Once the general domain is established, the engine shifts focus to analysing the micro context. Here, it examines specific terms, entities, and subtopics mentioned in the query or in related search patterns to identify fine-grained relevance. This step allows Google to pinpoint the exact aspect of a topic that interests the user — whether it’s “treatment options” within medicine or “ticket prices” within travel — helping refine which documents best satisfy that intent.
After both levels of analysis, the system scores and blends the findings. Macro and micro context signals are combined into a unified relevance score that balances broad topical alignment with precise intent matching. This blended scoring ensures that results are both contextually appropriate and specifically useful to the user’s current information needs.
Finally, the search engine returns results tailored to intent. The SERP reflects not only the overarching context of the topic but also the nuances inferred from the user’s words and behaviour. This is why Google’s results — and even its featured elements like People Also Ask or local packs — often seem to anticipate what the user meant, not just what they typed.

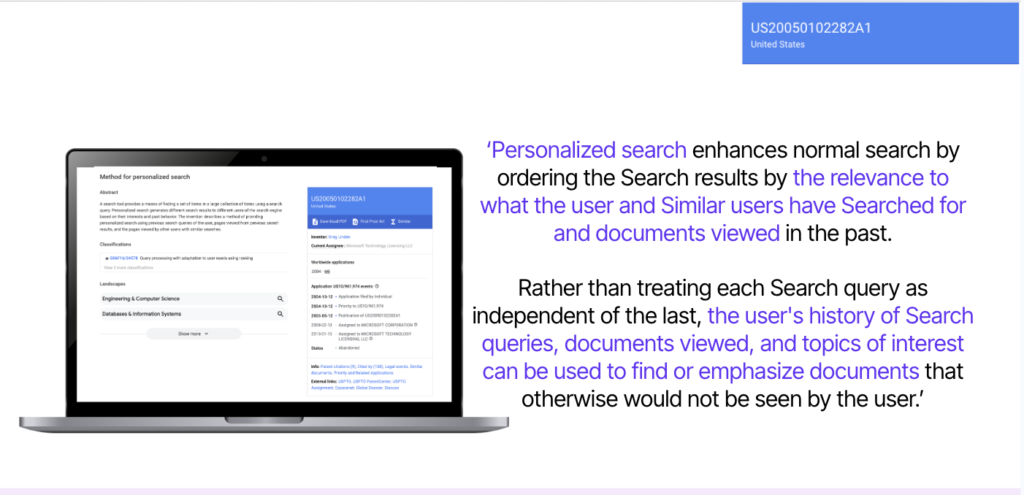
Beyond the single query: personalisation via session context
Context doesn’t reset between searches. Personalised search enhances “normal” ranking by using what the current user — and similar users — have searched, viewed, and found valuable. Rather than treating queries as isolated events, the system updates its understanding as behaviour unfolds, which can:
- Prioritise new, relevant results when previously seen results went unclicked or under-engaged
- Boost items related to what the user liked before, inferring preferences for domains, formats, and styles
- Surface content popular with similar users, amplifying items with strong engagement patterns in comparable cohorts
In short, what you and people like you find useful can elevate some results and suppress others.
When rankings rise vs. fall (and what to look for)
Understanding the mechanics behind ranking boosts and demotions turns what many perceive as rank volatility into actionable insight. These fluctuations aren’t arbitrary — they reflect how search engines interpret engagement patterns across both individuals and groups of similar users.
When rankings rise
Rankings tend to rise when Google detects strong engagement signals within a given query context. When certain pages repeatedly attract long clicks, low bounce rates, and consistent user satisfaction across similar searches, the system treats those pages as authoritative and rewarding. This collective behaviour signals that the content is delivering on intent, prompting Google to elevate it for new users entering the same search space.
A similar boost can occur at the individual level. If a user regularly interacts with a particular type of result — such as detailed product comparisons, tutorials, or listicles from a familiar publication — Google learns that preference. The algorithm then prioritises similar pages in future searches, assuming that their structure and style are more likely to meet that user’s needs.

When rankings fall
Conversely, rankings often drop when behaviour signals suggest that a page is no longer relevant or useful. If a user encounters the same URL multiple times in related searches but consistently skips it, Google interprets this as a lack of relevance and lowers its position for that person. This helps prevent stale or unhelpful results from reappearing unnecessarily.
Drops can also occur across groups of similar users when previously prominent pages start underperforming. If users in a shared interest group begin favouring newer or more engaging articles on the same topic, older pages may be quietly demoted to make space for fresher, better-aligned alternatives.
Together, these rise-and-fall dynamics illustrate how personalisation and engagement interact across micro (user-level) and macro (cohort-level) layers. Every skipped result, long dwell time, or revisited page subtly contributes to how search evolves — and why keeping content fresh, satisfying, and contextually precise matters more than ever.

Finding query context in your data
To operationalise query context, SEOs and marketers need to look beyond isolated keywords and examine how users formulate, refine, and connect their query sequences. Every variation reveals intent nuances — why a user searches, how they phrase a task, and what they expect next.
Identifying co-occurring query patterns
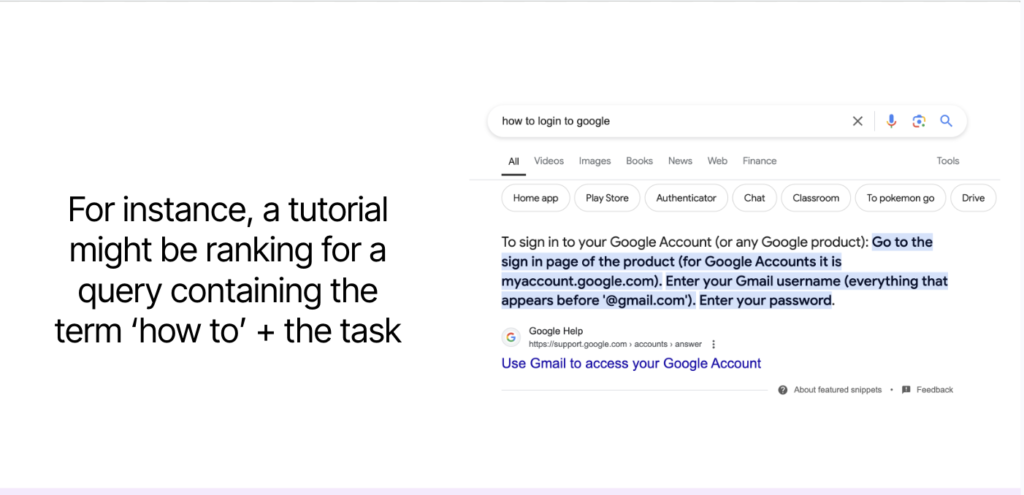
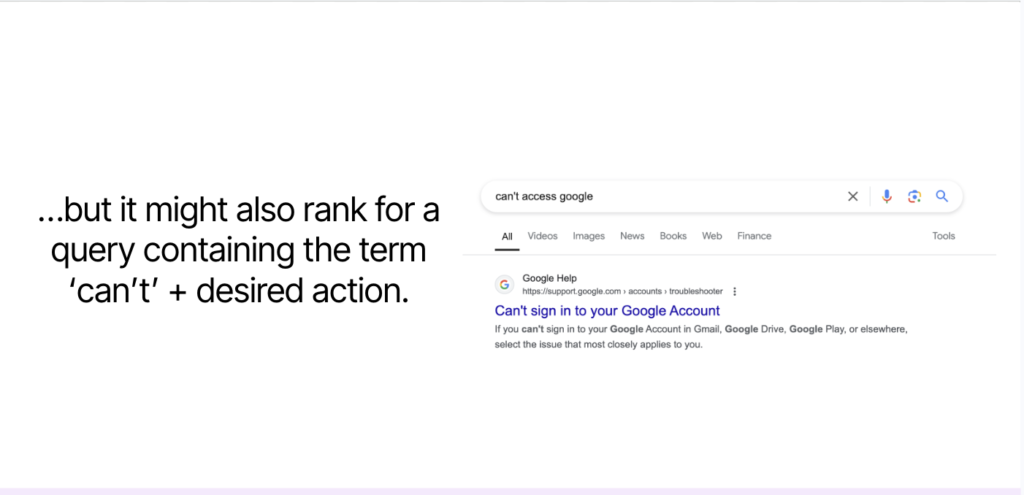
Understanding the sequences and variations that drive clicks to a given URL reveals how searchers frame the same task differently. Often, two or more seemingly distinct queries lead to the same result page because they express the same underlying intent. For example, a tutorial might rank for both “how to log into Google” and “can’t access Google.”
One phrasing signals a goal (“how to”), while the other reflects a problem (“can’t”). Addressing both angles within the same piece of content ensures your page satisfies the full spectrum of user needs without unnecessary duplication.
To uncover these relationships, analyse the query paths that users follow in Search Console and pay attention to recurring terms in SERP features like People Also Ask and Related Searches. Keyword tools and fuzzy matching techniques can also help cluster near-duplicate queries that describe the same action or challenge.
Grouping queries by themes, not terms
Once you’ve mapped co-occurring patterns, the next step is to group them by themes rather than individual words. Clustering queries based on shared meaning — whether through n-grams, entity extraction, or topic modelling — helps reveal how users conceptually group ideas. This thematic approach allows you to build pages that tackle broader tasks while leaving room for deeper, supporting content.
Lightweight keyword extraction can provide a quick view of shared intent, but more advanced entity-based clustering with KeyBERT offers insights into the semantic relationships between topics. For each cluster, assign a primary page that addresses the overarching theme and supporting subtopics that reflect common refinements.
This hierarchical structure allows your content to align naturally with how Google organises knowledge: broad macro context at the top, detailed micro context in the supporting layers.
Surfacing session context in your analytics
While query context focuses on what users search for in a single moment, session context reveals how those searches evolve over time. It’s the layer of meaning that emerges from repeated actions — the pages a user visits, the results they skip, and the sequences that connect one query to the next.
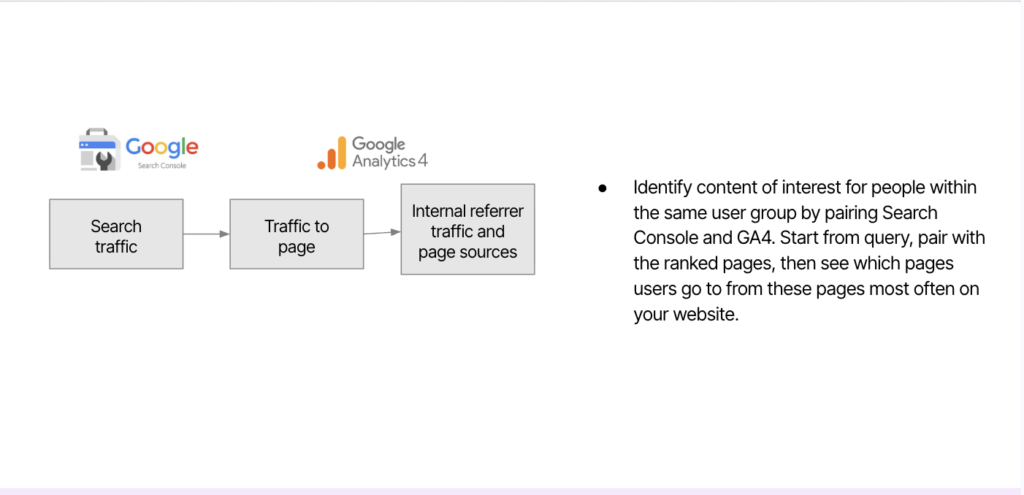
Blend Google Search Console and GA4 to map query to landing page to next-page paths
To capture session context effectively, combine Google Search Console (GSC) and Google Analytics 4 (GA4) data. GSC shows which queries bring users to your site, while GA4 reveals what happens next: how long they stay, where they go, and whether they convert or drop off. Pairing these data sources allows you to trace the full journey: the query that initiated the visit, the landing page that answered it, and the subsequent pages users explore.
Here is what you should do:
- Start with the query and ranking page (GSC)
- In GA4, analyse post-landing click paths and engagement outcomes
- Group paths by initial query to see common sequences and refine internal links and CTAs accordingly
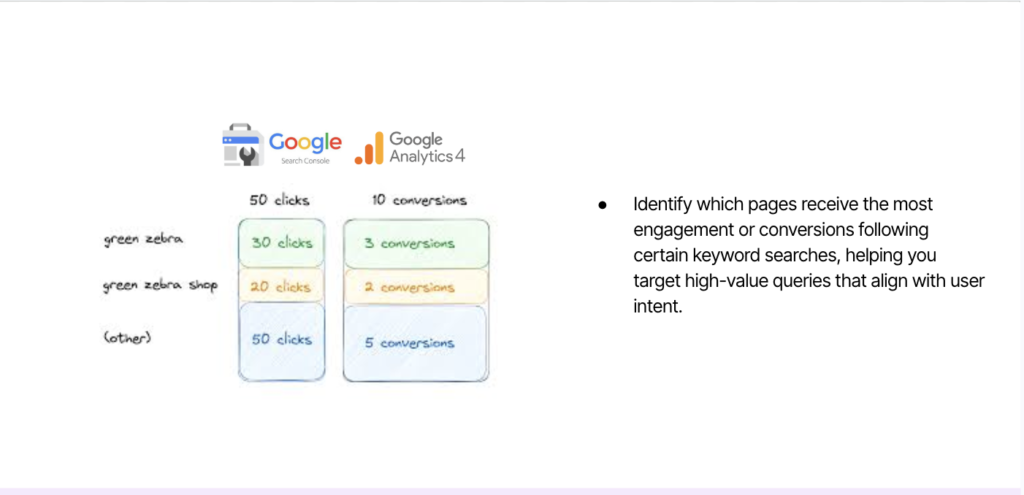
- Identify queries that correlate with high-value behaviour (engagement, conversions) and prioritise them in content updates
Tracking patterns that explain rank shifts
Session data can also explain why rankings rise or fall. Because Google personalises results based on both individual and cohort-level behaviour, content that repeatedly underperforms within sessions may be quietly demoted. Likewise, pages that sustain engagement and encourage deeper journeys can earn stronger relevance signals over time.
To diagnose these shifts, look for signs of intent cannibalisation within your own site. When two or more pages target the same underlying task, one may climb while the other declines — signalling that users consistently prefer one over the other. Identify these patterns by cross-referencing GSC data (to find overlapping queries) with analytics engagement metrics (to confirm which page holds attention).
The same logic applies when competing with other domains. If your traffic drops while a competitor rises for the same query set, it may indicate that searchers have found a more satisfying experience elsewhere. Pull these pages for revision or consolidation, focusing on improving depth, clarity, and user pathways.
Turning session insights into strategy
Once you’ve identified how users move through your site and how rankings react, use those insights to shape your content architecture. Design internal links that reflect the session journeys revealed in your analytics — connecting related topics in the same order users already follow them. Highlight pages that users frequently visit after entry as “next steps” or “recommended reads,” and make sure they’re easily discoverable from your key landing pages.
Session context shows what works in practice — which pages genuinely satisfy curiosity, which need reinforcement, and which fail to hold attention. Treat this data not as a report, but as a map of user intent, guiding where to expand, merge, or refine your topical clusters.
How AI search takes context and personalisation upstream
Everything we’ve covered so far describes how traditional search engines use context to re-rank a stable set of results. The query stays the same for every user; only the ordering changes based on personalisation signals.
AI search systems fundamentally change this. They move personalisation upstream — into the query generation process itself.
When you submit a query to Google’s AI Mode, ChatGPT, or Perplexity, the system doesn’t just search for what you typed. It expands your query into dozens of sub-queries through a process called query fan-out, retrieves information across those expansions, then synthesises a response. The critical shift is that those fan-out queries are themselves shaped by what the system knows about you.
Two users typing the identical query get different answers — not because of ranking changes, but because the questions the system asked on their behalf were different. Different context leads to different fan-out, which leads to different data retrieved, which ultimately produces a highly personalised view of the topic.
How it works: from memory and context to personalised fan-out
AI search platforms use a combination of session context, stored memory, and cross-product inference to shape how queries are expanded. The mechanisms vary by platform, but the principle is consistent: the system injects what it knows about you into the query expansion process before retrieval even begins.
Consider a concrete example. Two users both search for “best running shoes”:
User A — an experienced marathon runner in an urban area, whose search history indicates years of running experience — might trigger fan-out queries like:
- “marathon running shoes cushioning high mileage”
- “carbon plate marathon shoes performance”
- “lightweight racing flats urban marathon”
User B — a beginner preparing for their first marathon, located near trails where they train — might trigger entirely different expansions:
- “marathon training shoes for beginners mixed terrain”
- “trail to road running shoes for new marathoners”
- “cushioned shoes for long distance beginners”
Same input query. Same goal. Different contexts. Different questions asked on behalf of each user. Different documents retrieved. Different brands, products, and recommendations synthesised into the response.
This is not a subtle distinction. When personalisation affects ranking, you’re competing for a position within a stable results set. When personalisation affects query generation, you’re competing for inclusion in the query set itself. Your content might perfectly answer one user’s personalised fan-out and be completely invisible to another’s — not because it ranked poorly, but because the system never asked a question that would surface it.
The spectrum of inference depth across AI platforms
Not all AI search platforms personalise to the same degree. They sit on a spectrum from “only knows what you explicitly tell it” to “infers from your entire digital footprint”:
| Platform | Inference Depth | Primary Data Sources | Fan-Out Visibility |
|---|---|---|---|
| Perplexity | Shallow | Session context, explicit memories | High (Pro Search shows sub-queries) |
| Claude | Moderate | Saved memories, chat history, profile preferences | Low-Moderate (shows search query, not memory influence) |
| ChatGPT | Moderate | Saved memories, chat history patterns, session metadata | Low (query rewriting invisible) |
| Gemini | Deep (if enabled) | Gmail, Photos, YouTube, Search history, Workspace | Low (expansion not shown) |
| Copilot | Deepest | Full Microsoft 365 Graph — Teams, Outlook, OneDrive, Calendar | Low (grounding in preprocessing) |
The further right you go on this spectrum, the more the system knows about users even when the information is implicit. For platforms like Gemini and Copilot, context is inferred from your digital footprint rather than stated in a prompt.
Key takeaway: The platforms where personalisation matters most are the platforms where you can observe it least. You’re optimising for query expansions you’ll never see, shaped by user contexts you can’t access.
What your content competes against — by platform
This spectrum also determines what your content is competing against:
| Platform | Personalisation Depth | Your Content Competes Against | Strategic Priority |
|---|---|---|---|
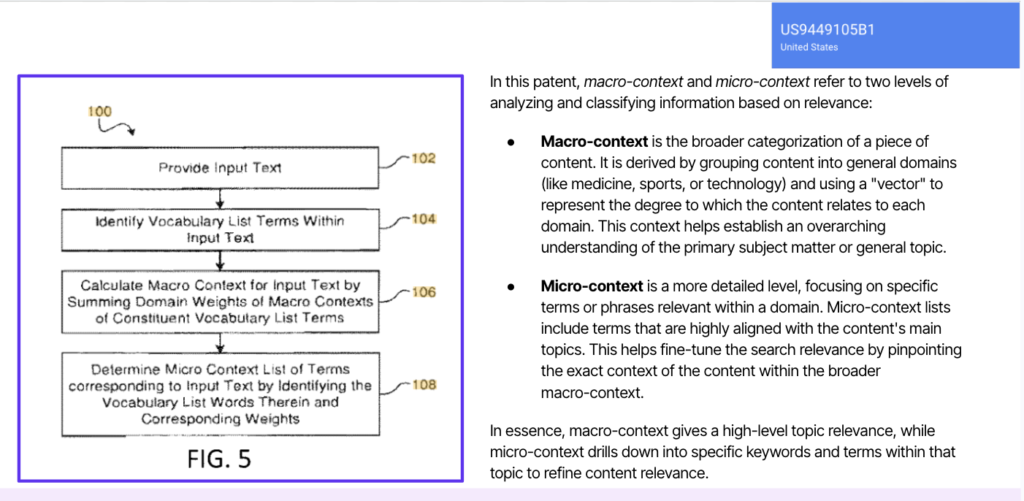
| Perplexity | Shallow (session + explicit) | Other public web content | Comprehensive topic coverage; visible in fan-out |
| ChatGPT / Claude | Moderate (explicit + inferred patterns) | Public web content + user’s stated context | Context-specific content that matches common user profiles |
| Gemini / AI Mode | Deep (cross-product inference) | Public content + inferred context from Google ecosystem | Content that addresses behavioural signals (not just stated needs) |
| Copilot | Deepest (full enterprise graph) | Public content + user’s internal documents and communications | Integration-ready content; bridges external expertise with internal application |
Tables are adapted from my in-depth article on iPullRank’s blog – How AI Search Personalizes Fan-Out Queries Using Memory and Context, highly recommended to read this to further understand query context and session context in AI search.
What this means for SEOs
The implications of personalised fan-out run deep, and they affect measurement, competitive analysis, and content strategy simultaneously.
For measurement: You can’t track a “ranking” when there’s no stable query to rank for. Your visibility becomes a distribution across user contexts, not a position. Impressions become aggregates that don’t tell you what percentage of relevant queries your content was even eligible for.
For competitive analysis: Brands you’ve dismissed as non-competitors might be capturing users whose personalised fan-outs align with their focused positioning. A smaller brand with highly specific, structured content can surface for users where a broader, more authoritative competitor’s content simply never enters the consideration set.
For content strategy: Keyword-based optimisation alone becomes insufficient. You need to optimise for the range of questions that different user contexts might generate around your topic. Think persona-based semantic topic clusters rather than single-keyword targeting.
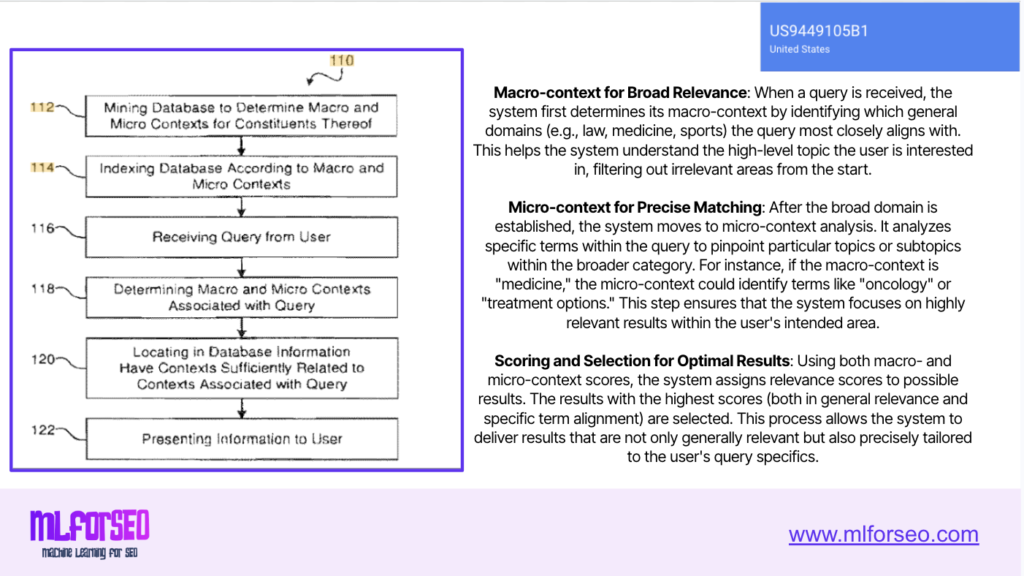
The filter bubble risk
There’s also a darker side to personalised fan-out. AI systems can drift from what users ask to what their profiles suggest they want. If your search history indicates interest in budget options, AI systems may constrain fan-out queries to budget-focused angles — even when you’d happily pay more for quality in this particular search. Your preferences might have changed, but the system assumes consistency. You never see the premium options because the fan-out queries never asked about them.
For brands, this creates visibility gaps that are equally invisible. Your content might be the perfect answer for what a user actually needs — but if their profile suggests they need something else, the fan-out queries never give your content a chance.
Adapting your content strategy for context-driven search
The strategic response to personalised fan-out isn’t to game the personalisation signals — you can’t access them. Instead, focus on fundamentals that make your content robust enough to surface across diverse user contexts and specific enough to be the best answer when you do surface.
Semantic SEO becomes non-negotiable
If personalisation shapes which entities and concepts appear in fan-out queries, your content needs to be unambiguously associated with the right entities and concepts. Structured data and an enterprise knowledge graph — with bidirectional entity relationships and detailed tagging — make your content more easily parseable by both traditional search engines and AI systems.
Niche authority beats broad evergreen content
Personalised fan-out rewards specificity. When the system generates sub-queries like “best trail running shoes for first marathon under €150,” it’s looking for content that addresses that specific intersection. A 10,000-word guide that briefly mentions trail running, briefly mentions marathon training, and briefly mentions budget considerations is less relevant than a 1,500-word piece that deeply addresses exactly that combination.
Think contextual intersections, not keywords
Stop thinking about keywords as single dimensions (“running shoes”) and start thinking about contextual intersections — multi-dimensional combinations like “running shoes” + “marathon training” + “trail terrain” + “beginner level” + “budget conscious.” AI search fan-outs generate queries along these intersections. Your content strategy should map the intersections relevant to your business and ensure you have content addressing each one within your core pages closest to purchase.
Entity consistency across the user journey
AI systems build entity associations from your entire content footprint — not just individual pages. If your brand is associated with “premium performance” in some content and “budget-friendly” in other content, AI systems receive mixed signals about who you serve. Decide who you are, who you serve, and what contexts you want to own — then ensure your entire content ecosystem reinforces those associations consistently.
For a deeper exploration of how each AI search platform handles memory, context, and personalised fan-out — including experiments and platform-specific documentation — read the full analysis: How AI Search Personalizes Fan-Out Queries Using Memory and Context.
From insights to application: a tactical checklist
Turning these concepts into practice means translating context analysis into specific actions. Here’s a checklist to run this quarter:
- Map your intent clusters. Group all queries that lead to the same solutions — including both “how to” and “can’t” phrasing patterns — and make sure your main pages address them comprehensively.
- Run a GSC → GA4 path study. For your top ten landing queries, trace the next pages users visit on your site. If you notice strong but unsupported pathways, add or update internal links that guide users naturally along those journeys.
- Find and fix cannibalisation. Look for pairs of pages where one URL’s rise coincides with another’s decline for the same intent. Consolidate overlapping pages or differentiate them by purpose to eliminate internal competition.
- Identify “popular among similar users” themes. Select three themes in your niche, identify subtopics and entities that consistently appear across winning pages (both your own and competitors’), and schedule deeper updates or new articles that capture that shared interest.
- Audit your entity consistency. Review your content across all channels — website, social, forums, YouTube — and ensure your brand positioning and entity associations are coherent. Mixed signals dilute your authority with AI systems.
- Prepare for seasonal patterns. If user behaviour repeats cyclically (around holidays, sales periods, or industry events), standardise your page templates and internal link modules so they’re ready to capture returning demand without structural changes.
- Commit to ongoing review. Revisit your query clusters and session paths monthly, refreshing high-interest pages and adjusting hub-to-spoke links as patterns evolve. Regular refinement keeps your architecture responsive to how users — and algorithms — redefine relevance over time.
📚 Deepen your knowledge: Semantic AI-Powered Keyword Research Course
This blog post covers the key concepts from the lesson on Query Context and Session Context from the Semantic AI-Powered SEO Keyword Research course at the MLforSEO Academy. The course expands on everything covered here — from Google’s patents on contextual search to practical demos for identifying session patterns with real analytics data.
In the course, you’ll explore:
- How Google’s patents define macro and micro context and how those map to the Text Classification API, topic modelling, and entity identification
- Practical walkthroughs using Google Search Console and GA4 to trace query → landing → next-page paths
- How to identify and resolve intent cannibalisation using semantic analysis
- Templates for competitor analysis and trending topic identification
📖 Related glossary terms from MLforSEO
Brush up on the key concepts from this post in the MLforSEO Glossary:
- Query Context — The context a user provides in individual queries via the words and modifiers in their search.
- Query Path — The logical progression of search queries a user performs until they satisfy their intent, across single or multiple sessions.
- Query Sequence — The series or order of related search queries performed within a single search session.
- Query Augmentation — The process of expanding or modifying a query to improve search accuracy and relevance.
- Query Distance — A measure of semantic similarity between two queries, often calculated via fuzzy matching.
Recommended additional reading
- Google Patent — User-context-based search engine — Defines macro and micro context for scoring search results.
- Google Patent — Context-based filtering of search results — Describes how contextual signals filter and rank documents.
- Bill Slawski — Context Clusters in Search Query Suggestions (SEO by the Sea) — Explains the role of session context in determining which query suggestions Google provides.
- Lazarina Stoy — How AI Search Personalizes Fan-Out Queries Using Memory and Context (iPullRank) — A comprehensive analysis of how ChatGPT, Gemini, Perplexity, Claude, and Copilot use memory and context to personalise query expansion.
Lazarina Stoy is a Digital Marketing Consultant with expertise in SEO, Machine Learning, and Data Science, and the founder of MLforSEO. Lazarina’s expertise lies in integrating marketing and technology to improve organic visibility strategies and implement process automation.
A University of Strathclyde alumna, her work spans across sectors like B2B, SaaS, and big tech, with notable projects for AWS, Extreme Networks, neo4j, Skyscanner, and other enterprises.
Lazarina champions marketing automation, by creating resources for SEO professionals and speaking at industry events globally on the significance of automation and machine learning in digital marketing. Her contributions to the field are recognized in publications like Search Engine Land, Wix, and Moz, to name a few.
As a mentor on GrowthMentor and a guest lecturer at the University of Strathclyde, Lazarina dedicates her efforts to education and empowerment within the industry.
- Lazarina Stoy.

- Lazarina Stoy.
- Lazarina Stoy.

- Lazarina Stoy.